library(tidyverse)
library(readxl)
library(epifitter)
library(emmeans)
library(multcomp)aula4
Aula 4 — comparação de médias: teste t, testes não paramétricos e ANOVA
Objetivos da aula
Nesta aula, vamos organizar uma sequência de análises estatísticas voltadas à comparação de médias em situações comuns em experimentos biológicos e agronômicos. O foco será em três contextos:
- comparação entre dois grupos independentes;
- comparação entre duas condições medidas nos mesmos indivíduos;
- comparação entre três ou mais grupos.
Ao longo da aula, usaremos exemplos reais do arquivo dados_diversos.xlsx, discutindo a lógica estatística, as hipóteses, as fórmulas e a implementação em R.
Pacotes utilizados
Parte 1 — Leitura dos dados e cálculo da AUDPC
Leitura da planilha curve
O primeiro conjunto de dados contém avaliações de severidade ao longo do tempo, em dois tratamentos de irrigação. Antes de comparar tratamentos, é útil visualizar a progressão temporal da doença.
dados <- read_excel("dados_diversos.xlsx", sheet = "curve")
glimpse(dados)Rows: 60
Columns: 4
$ Irrigation <chr> "Furrow", "Furrow", "Furrow", "Furrow", "Furrow", "Furrow",…
$ rep <dbl> 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2,…
$ day <dbl> 0, 0, 0, 7, 7, 7, 14, 14, 14, 21, 21, 21, 28, 28, 28, 35, 3…
$ severity <dbl> 0.010, 0.010, 0.010, 0.036, 0.036, 0.040, 0.097, 0.097, 0.1…head(dados)# A tibble: 6 × 4
Irrigation rep day severity
<chr> <dbl> <dbl> <dbl>
1 Furrow 1 0 0.01
2 Furrow 2 0 0.01
3 Furrow 3 0 0.01
4 Furrow 1 7 0.036
5 Furrow 2 7 0.036
6 Furrow 3 7 0.04 Resumo gráfico da severidade ao longo do tempo
A seguir, calculamos a média e o desvio-padrão da severidade, em porcentagem, para cada combinação de tratamento e tempo de avaliação.
dados |>
group_by(Irrigation, day) |>
summarise(
mean_sev = mean(severity * 100),
sd_sev = sd(severity * 100),
.groups = "drop"
) |>
ggplot(aes(x = day, y = mean_sev, color = Irrigation, group = Irrigation)) +
geom_point(size = 2) +
geom_line() +
geom_errorbar(aes(ymin = mean_sev - sd_sev,
ymax = mean_sev + sd_sev),
width = 0.1) +
ylim(0, 100) +
labs(
x = "Dias após a avaliação inicial",
y = "Severidade média (%)",
color = "Irrigação"
) +
theme_minimal()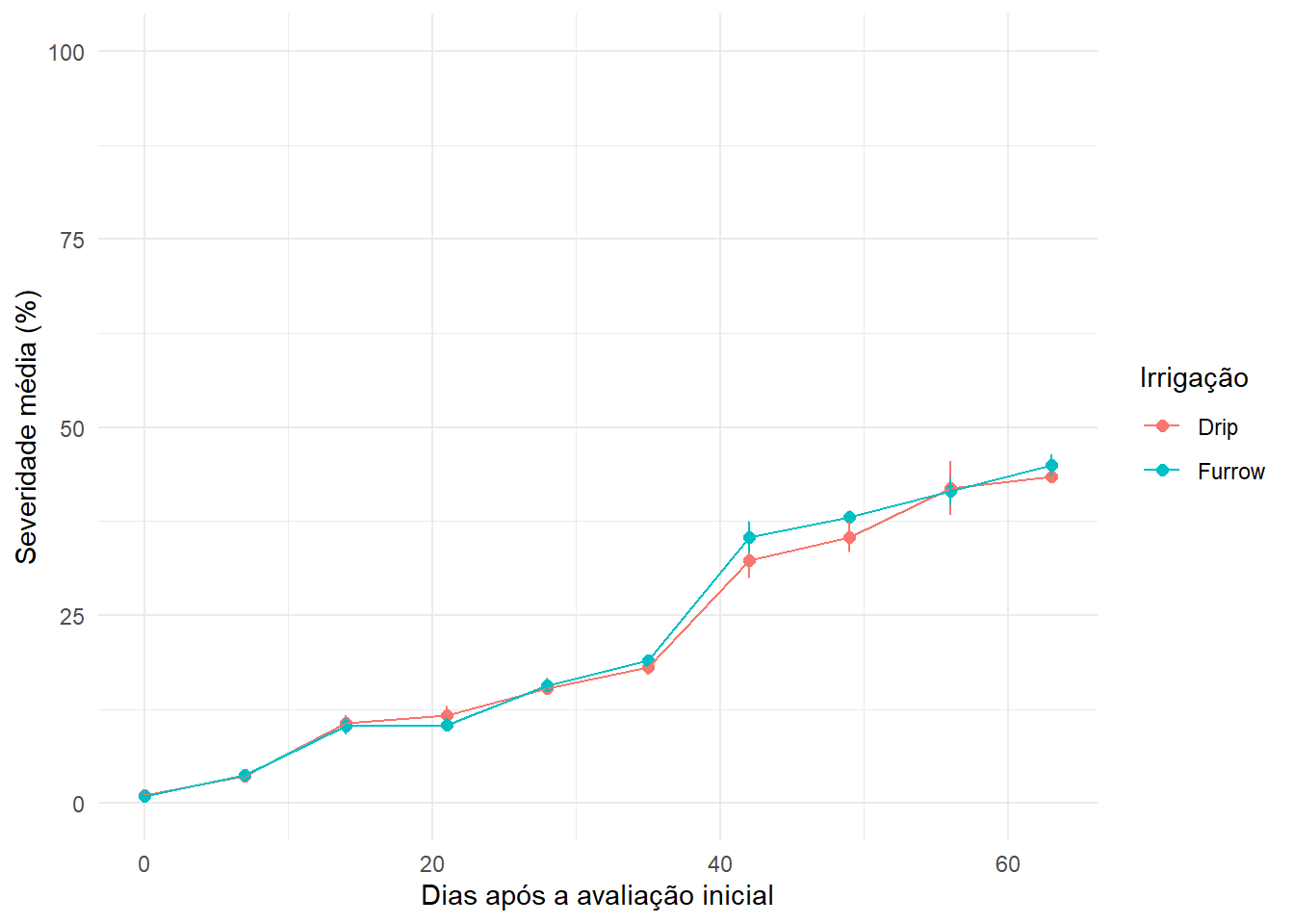
Área abaixo da curva de progresso da doença
Em estudos epidemiológicos, muitas vezes desejamos resumir toda a curva de progresso em uma única medida. Uma das medidas mais usadas é a AUDPC (Area Under the Disease Progress Curve), ou área abaixo da curva de progresso da doença.
A fórmula geral da AUDPC, pelo método dos trapézios, é:
\[ AUDPC = \sum_{i=1}^{n-1} \left( \frac{y_i + y_{i+1}}{2} \right)(t_{i+1} - t_i) \]
em que:
- \(y_i\) e \(y_{i+1}\) são as severidades observadas em duas avaliações consecutivas;
- \(t_i\) e \(t_{i+1}\) são os tempos correspondentes;
- \(n\) é o número de avaliações.
Essa estatística resume a intensidade da doença ao longo do tempo. Quanto maior a AUDPC, maior a quantidade acumulada de doença no período avaliado.
dados2 <- dados |>
group_by(Irrigation, rep) |>
summarise(
audpc = AUDPC(day, severity),
.groups = "drop"
) |>
mutate(Irrigation = as.factor(Irrigation))
dados2# A tibble: 6 × 3
Irrigation rep audpc
<fct> <dbl> <dbl>
1 Drip 1 13.0
2 Drip 2 13.9
3 Drip 3 13.3
4 Furrow 1 13.5
5 Furrow 2 14.0
6 Furrow 3 13.9Estatísticas descritivas da AUDPC
Antes de qualquer teste formal, é recomendável resumir os dados por tratamento.
resumo_audpc <- dados2 |>
group_by(Irrigation) |>
summarise(
mean_audpc = mean(audpc),
sd_audpc = sd(audpc),
n = n(),
se_audpc = sd_audpc / sqrt(n),
ic_95 = qt(0.975, df = n - 1) * se_audpc,
.groups = "drop"
)
resumo_audpc# A tibble: 2 × 6
Irrigation mean_audpc sd_audpc n se_audpc ic_95
<fct> <dbl> <dbl> <int> <dbl> <dbl>
1 Drip 13.4 0.453 3 0.261 1.13
2 Furrow 13.8 0.245 3 0.142 0.609Gráfico com média e desvio-padrão
resumo_audpc |>
ggplot(aes(x = Irrigation, y = mean_audpc)) +
geom_col(width = 0.5, fill = "gray80") +
geom_point(size = 2) +
geom_errorbar(aes(ymin = mean_audpc - sd_audpc,
ymax = mean_audpc + sd_audpc),
width = 0.1) +
labs(x = "Irrigação", y = "AUDPC média (± DP)") +
theme_minimal()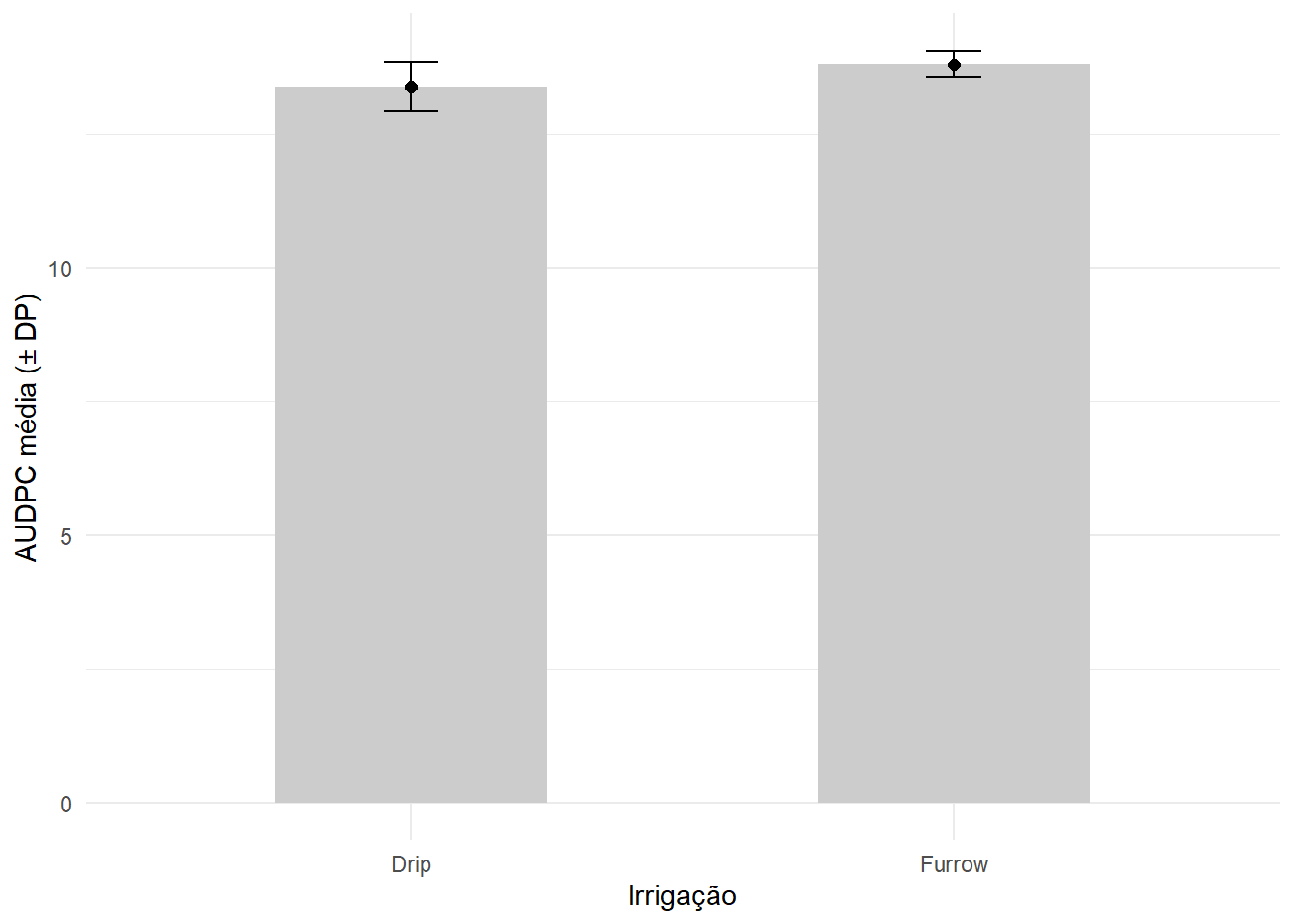
Gráfico com média e erro-padrão da média
O erro-padrão da média é dado por:
\[ EP(\bar{x}) = \frac{s}{\sqrt{n}} \]
em que:
- \(s\) é o desvio-padrão amostral;
- \(n\) é o tamanho da amostra.
resumo_audpc |>
ggplot(aes(x = Irrigation, y = mean_audpc)) +
geom_col(width = 0.5, fill = "gray80") +
geom_point(size = 2) +
geom_errorbar(aes(ymin = mean_audpc - se_audpc,
ymax = mean_audpc + se_audpc),
width = 0.1) +
labs(x = "Irrigação", y = "AUDPC média (± EP)") +
theme_minimal()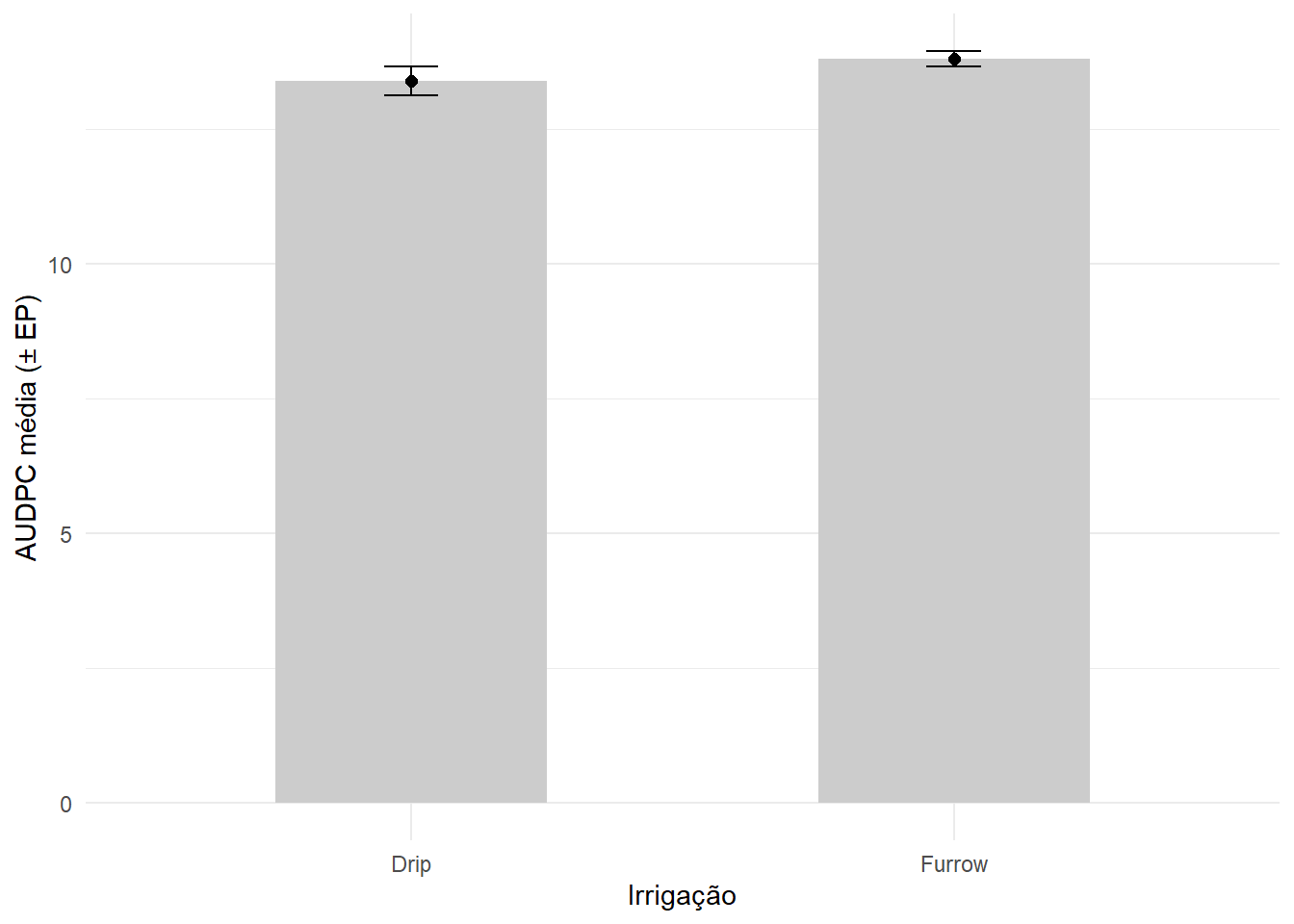
Gráfico com intervalo de confiança de 95%
O intervalo de confiança para a média pode ser escrito como:
\[ \bar{x} \pm t_{\alpha/2,\, n-1} \times \frac{s}{\sqrt{n}} \]
em que \(t_{\alpha/2,\, n-1}\) é o quantil da distribuição t de Student com \(n-1\) graus de liberdade.
resumo_audpc |>
ggplot(aes(x = Irrigation, y = mean_audpc)) +
geom_col(width = 0.5, fill = "skyblue") +
geom_point(size = 2) +
geom_errorbar(aes(ymin = mean_audpc - ic_95,
ymax = mean_audpc + ic_95),
width = 0.1) +
labs(x = "Irrigação", y = "AUDPC média (IC 95%)") +
theme_minimal()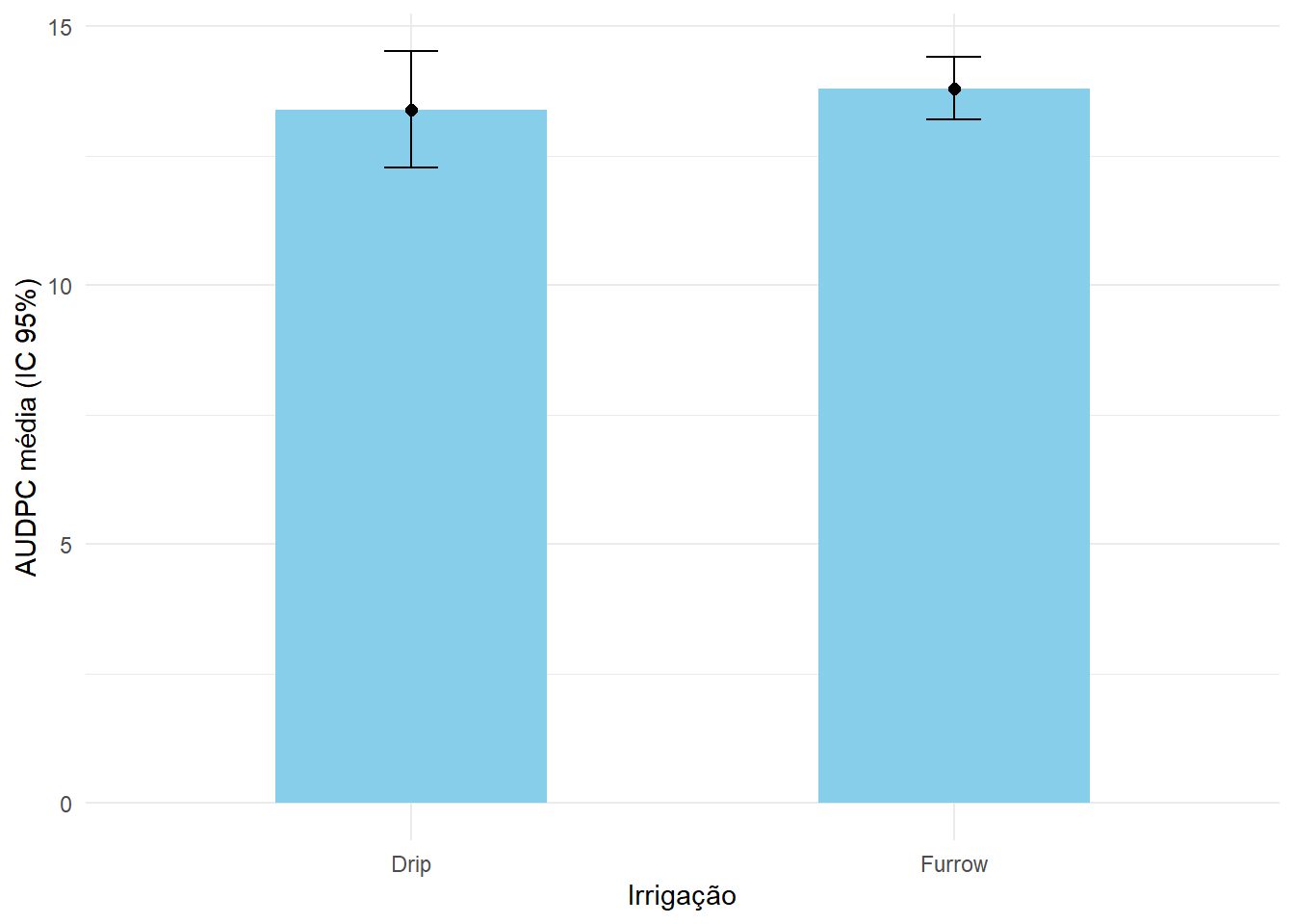
Parte 2 — Teste t para dois grupos independentes
Quando usar?
O teste t para amostras independentes é usado quando queremos comparar as médias de dois grupos distintos, assumindo independência entre as observações.
Neste caso, vamos comparar a AUDPC entre os dois tratamentos de irrigação.
Hipóteses
As hipóteses do teste são:
\[ H_0: \mu_1 = \mu_2 \]
\[ H_1: \mu_1 \neq \mu_2 \]
ou seja, a hipótese nula afirma que as médias populacionais são iguais, enquanto a hipótese alternativa afirma que elas diferem.
Estatística do teste
Quando as variâncias são assumidas como diferentes, usa-se a versão de Welch do teste t, cuja estatística é:
\[ t = \frac{\bar{x}_1 - \bar{x}_2}{\sqrt{\frac{s_1^2}{n_1} + \frac{s_2^2}{n_2}}} \]
em que:
- \(\bar{x}_1\) e \(\bar{x}_2\) são as médias amostrais;
- \(s_1^2\) e \(s_2^2\) são as variâncias amostrais;
- \(n_1\) e \(n_2\) são os tamanhos amostrais.
Aplicação em R
teste_t_audpc <- t.test(audpc ~ Irrigation, data = dados2)
teste_t_audpc
Welch Two Sample t-test
data: audpc by Irrigation
t = -1.3773, df = 3.079, p-value = 0.26
alternative hypothesis: true difference in means between group Drip and group Furrow is not equal to 0
95 percent confidence interval:
-1.3421436 0.5231436
sample estimates:
mean in group Drip mean in group Furrow
13.38983 13.79933 Interpretação
O objeto retornado informa:
- a estatística t;
- os graus de liberdade;
- o valor de p;
- o intervalo de confiança para a diferença entre médias;
- as médias estimadas em cada grupo.
Se o valor de p for menor que o nível de significância adotado, rejeitamos \(H_0\) e concluímos que há evidência de diferença entre as médias.
Parte 3 — Teste t pareado
Situação experimental
Agora usaremos a planilha escala, em que os mesmos avaliadores foram medidos em duas condições de avaliação. Nesse caso, as observações não são independentes, pois cada avaliador aparece nas duas condições.
Logo, o teste adequado é o teste t pareado.
escala <- read_excel("dados_diversos.xlsx", sheet = "escala")
glimpse(escala)Rows: 20
Columns: 7
$ assessment <chr> "Unaided", "Unaided", "Unaided", "Unaided", "Unaided"…
$ rater <chr> "A", "B", "C", "D", "E", "F", "G", "H", "I", "J", "A"…
$ acuracia <dbl> 0.8092131, 0.7219848, 0.4000000, 0.8175313, 0.7476691…
$ precisao <dbl> 0.8262697, 0.7284040, 0.7149415, 0.8187018, 0.7532589…
$ vies_geral <dbl> 0.9793570, 0.9911874, 0.7827190, 0.9985702, 0.9925792…
$ vies_sistematico <dbl> 1.1872167, 0.9217054, 1.1600785, 0.9481874, 1.1038873…
$ vies_constante <dbl> 0.1123982, -0.1055045, 0.7301412, -0.0056930, 0.07194…head(escala)# A tibble: 6 × 7
assessment rater acuracia precisao vies_geral vies_sistematico vies_constante
<chr> <chr> <dbl> <dbl> <dbl> <dbl> <dbl>
1 Unaided A 0.809 0.826 0.979 1.19 0.112
2 Unaided B 0.722 0.728 0.991 0.922 -0.106
3 Unaided C 0.4 0.715 0.783 1.16 0.730
4 Unaided D 0.818 0.819 0.999 0.948 -0.00569
5 Unaided E 0.748 0.753 0.993 1.10 0.0719
6 Unaided F 0.45 0.751 0.925 0.802 0.336 Visualização inicial
escala |>
ggplot(aes(x = assessment, y = log(acuracia))) +
geom_boxplot(outlier.colour = NA) +
geom_jitter(width = 0.1, alpha = 0.7) +
labs(x = "Tipo de avaliação", y = "log(acuracia)") +
theme_minimal()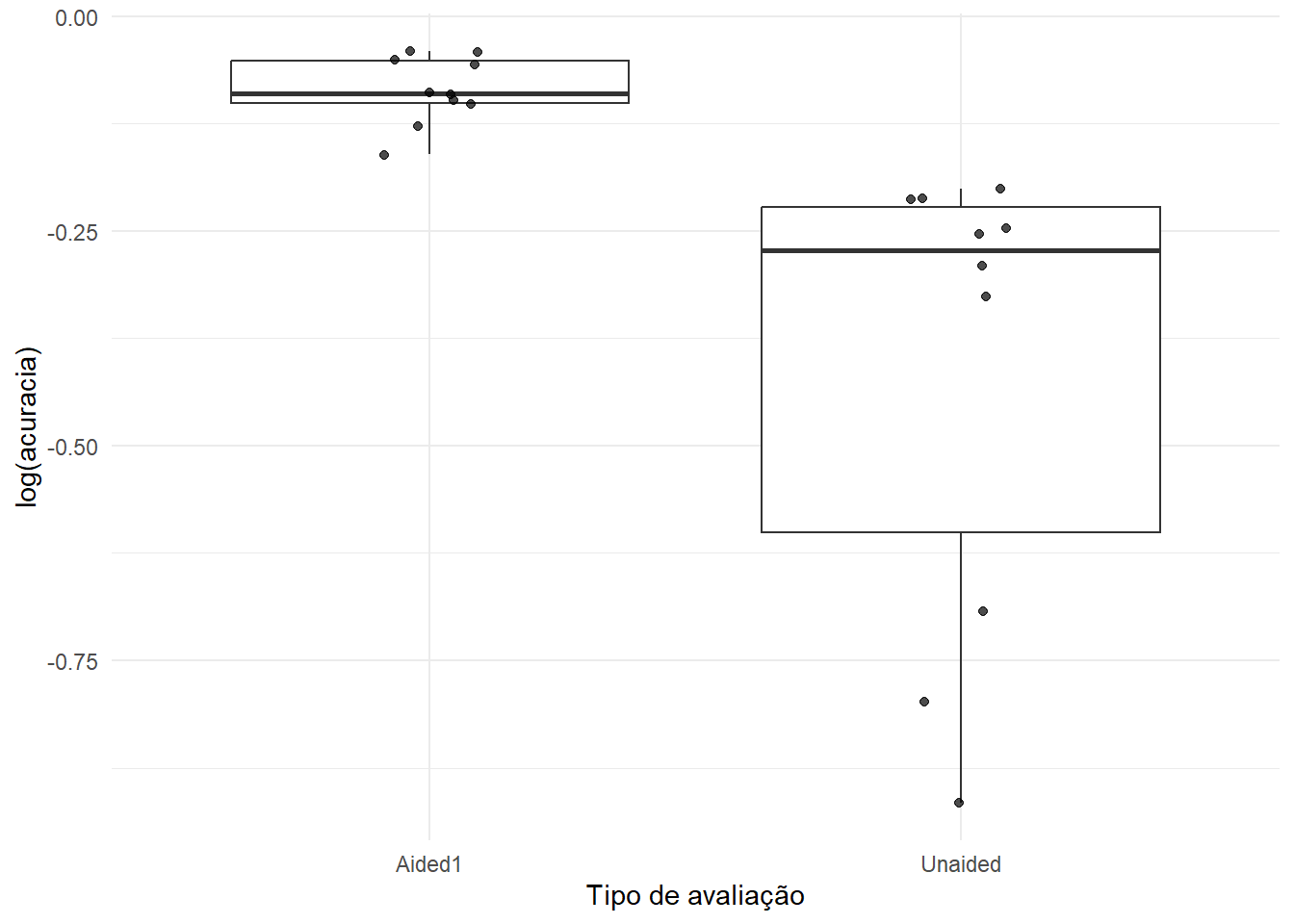
Organização dos dados em formato largo
Para o teste pareado, é conveniente reorganizar a tabela de forma que cada linha corresponda a um avaliador e cada coluna a uma condição.
escala_wide <- escala |>
dplyr::select(rater, assessment, acuracia) |>
pivot_wider(
names_from = assessment,
values_from = acuracia
)
escala_wide# A tibble: 10 × 3
rater Unaided Aided1
<chr> <dbl> <dbl>
1 A 0.809 0.907
2 B 0.722 0.913
3 C 0.4 0.915
4 D 0.818 0.960
5 E 0.748 0.959
6 F 0.45 0.903
7 G 0.807 0.851
8 H 0.781 0.880
9 I 0.776 0.950
10 J 0.5 0.944Lógica do teste t pareado
No teste pareado, o interesse recai sobre a diferença entre as duas medidas do mesmo indivíduo:
\[ d_i = x_{i1} - x_{i2} \]
O teste é então realizado sobre a média das diferenças:
\[ H_0: \mu_d = 0 \]
\[ H_1: \mu_d \neq 0 \]
A estatística do teste é:
\[ t = \frac{\bar{d}}{s_d / \sqrt{n}} \]
em que:
- \(\bar{d}\) é a média das diferenças;
- \(s_d\) é o desvio-padrão das diferenças;
- \(n\) é o número de pares.
Aplicação do teste t pareado
teste_t_pareado <- t.test(
escala_wide$Aided1,
escala_wide$Unaided,
paired = TRUE
)
teste_t_pareado
Paired t-test
data: escala_wide$Aided1 and escala_wide$Unaided
t = 4.4266, df = 9, p-value = 0.001655
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
0.1159591 0.3583453
sample estimates:
mean difference
0.2371522 Visualização das diferenças
Uma forma útil de compreender o teste pareado é visualizar explicitamente as diferenças entre pares.
diferencas <- escala_wide |>
mutate(diff = Aided1 - Unaided)
diferencas |>
ggplot(aes(x = diff)) +
geom_histogram(bins = 10, color = "white") +
labs(x = "Diferença pareada (Aided1 - Unaided)", y = "Frequência") +
theme_minimal()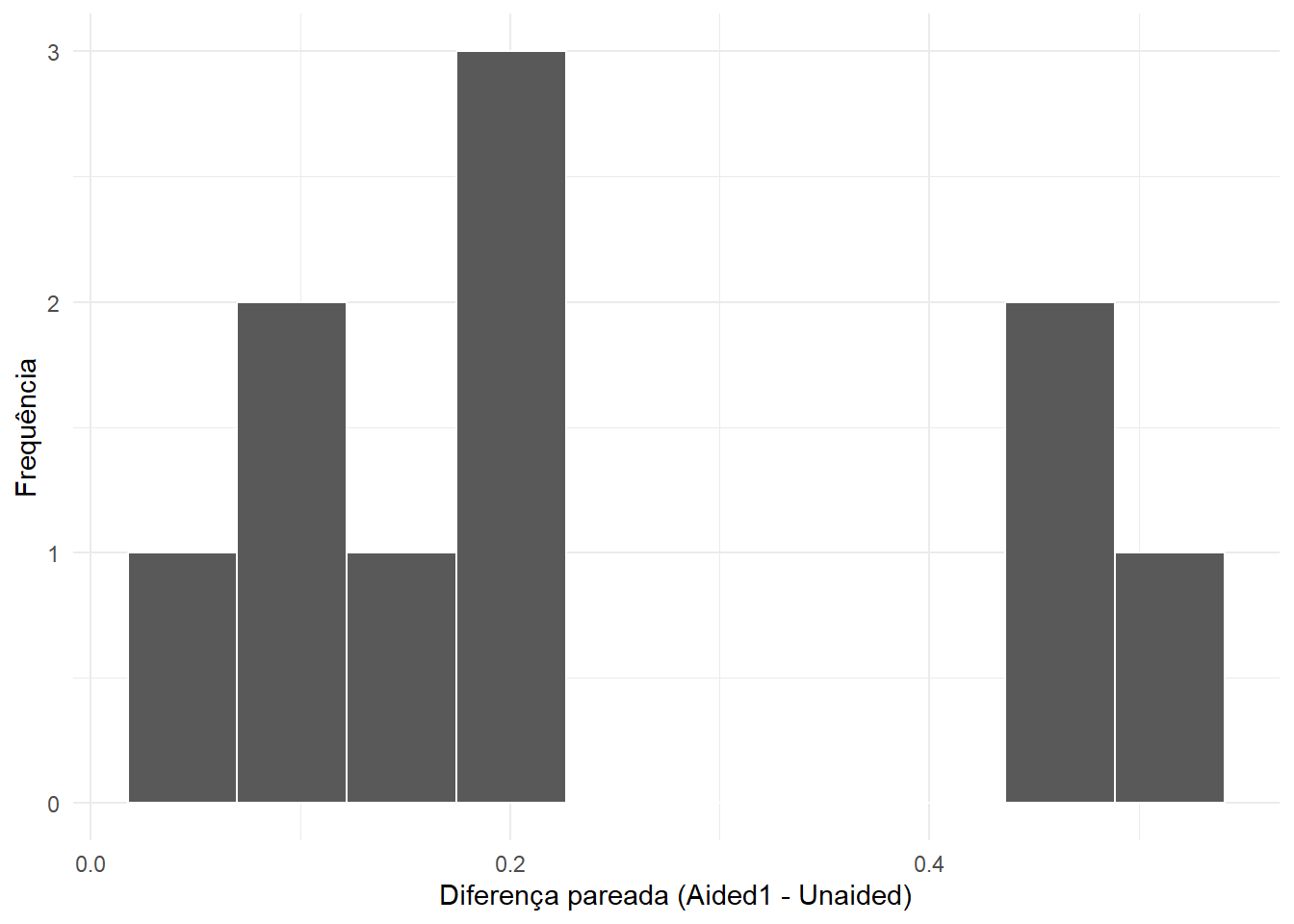
Parte 4 — Verificação da normalidade e alternativa não paramétrica
Por que verificar a normalidade?
O teste t pareado assume que as diferenças entre pares seguem, aproximadamente, uma distribuição normal. Não é necessário que cada grupo separadamente seja normal; o foco está nas diferenças.
Inspeção gráfica e teste de Shapiro-Wilk
qqnorm(diferencas$diff)
qqline(diferencas$diff)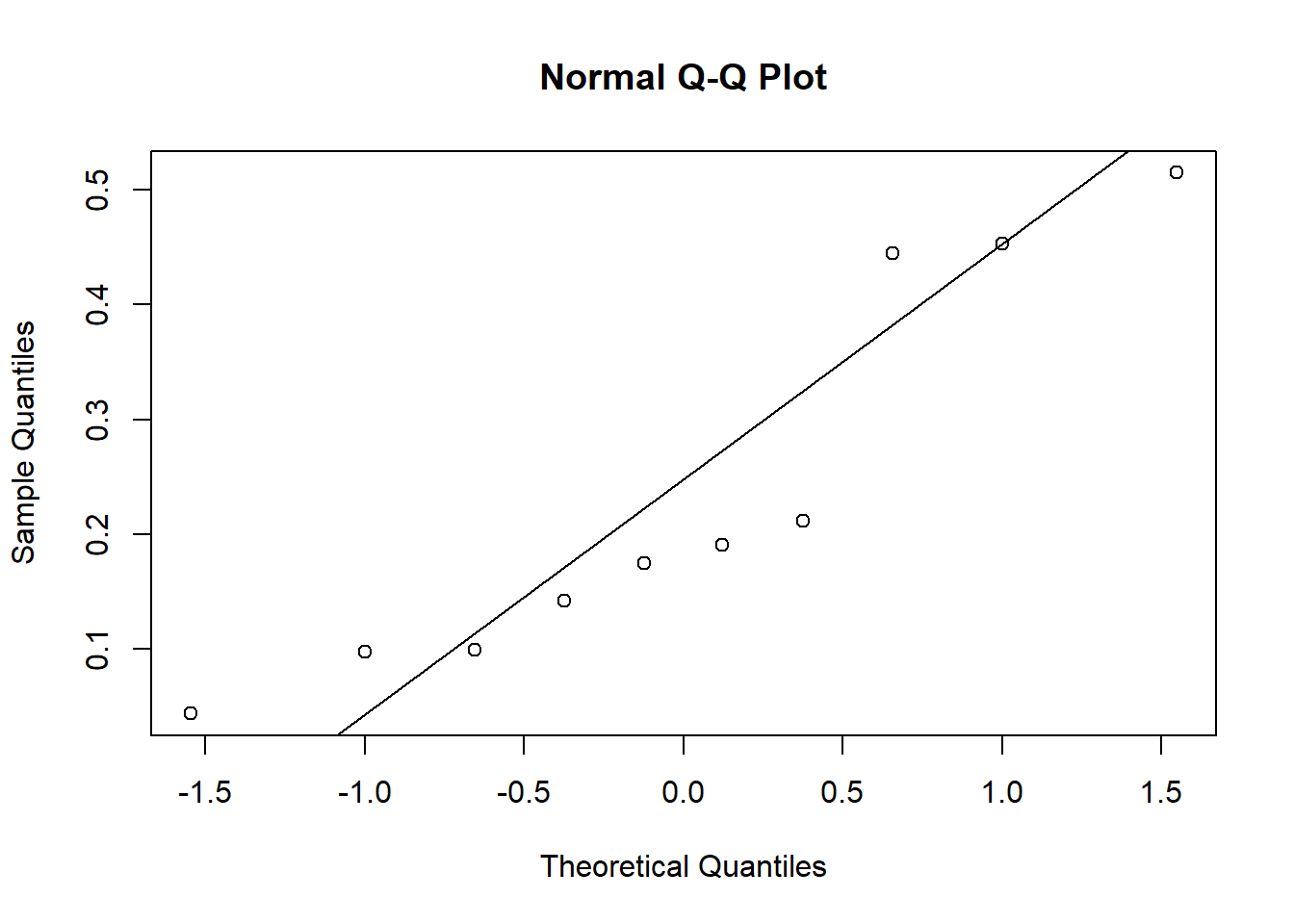
shapiro.test(diferencas$diff)
Shapiro-Wilk normality test
data: diferencas$diff
W = 0.8566, p-value = 0.06956Teste não paramétrico de Wilcoxon pareado
Se a suposição de normalidade das diferenças for claramente violada, uma alternativa clássica é o teste de postos sinalizados de Wilcoxon.
Esse teste não compara médias, mas sim a tendência central das diferenças, com base nas magnitudes ordenadas dos desvios em relação a zero.
As hipóteses continuam sendo, em essência:
\[ H_0: \text{a distribuição das diferenças é centrada em zero} \]
\[ H_1: \text{a distribuição das diferenças não é centrada em zero} \]
teste_wilcox <- wilcox.test(
escala_wide$Unaided,
escala_wide$Aided1,
paired = TRUE
)
teste_wilcox
Wilcoxon signed rank exact test
data: escala_wide$Unaided and escala_wide$Aided1
V = 0, p-value = 0.001953
alternative hypothesis: true location shift is not equal to 0Comentário metodológico
Em conjuntos de dados pequenos, é recomendável usar o gráfico QQ, o histograma das diferenças e o conhecimento do experimento em conjunto, em vez de depender exclusivamente do teste de Shapiro-Wilk. Pequenos desvios da normalidade nem sempre invalidam o teste t, sobretudo quando não há assimetria extrema ou valores discrepantes muito influentes.
Parte 5 — ANOVA para comparação de três ou mais grupos
Situação experimental
Agora analisaremos a planilha micelial, que contém dados de taxa de crescimento micelial (tcm) para diferentes espécies.
Quando o objetivo é comparar a média de uma variável resposta entre três ou mais grupos, a abordagem clássica é a análise de variância (ANOVA).
micelial <- read_excel("dados_diversos.xlsx", sheet = "micelial")
micelial |>
count(especie)# A tibble: 5 × 2
especie n
<chr> <int>
1 Fasi 6
2 Faus 6
3 Fcor 6
4 Fgra 6
5 Fmer 6Visualização exploratória
set.seed(2)
micelial |>
ggplot(aes(x = reorder(especie, tcm), y = tcm)) +
geom_boxplot(outlier.colour = NA) +
geom_jitter(width = 0.2, alpha = 0.7) +
coord_flip() +
labs(x = "Espécie", y = "Taxa de crescimento micelial") +
theme_minimal()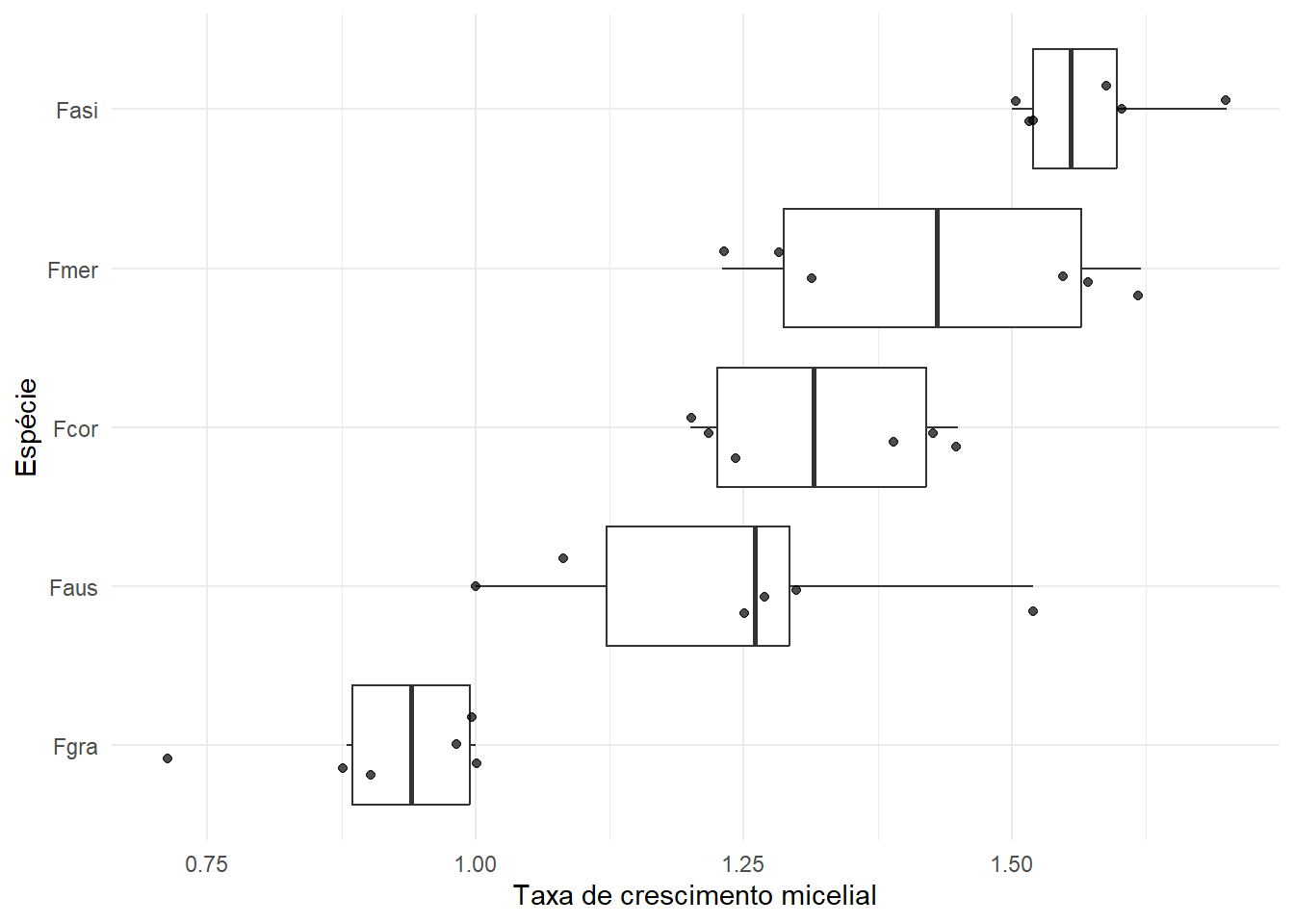
Modelo de ANOVA
O modelo clássico de ANOVA de um fator pode ser escrito como:
\[ Y_{ij} = \mu + \tau_i + \varepsilon_{ij} \]
em que:
- \(Y_{ij}\) é a observação da unidade \(j\) no grupo \(i\);
- \(\mu\) é a média geral;
- \(\tau_i\) é o efeito do grupo \(i\);
- \(\varepsilon_{ij}\) é o erro aleatório, assumido com distribuição normal, média zero e variância constante.
As hipóteses são:
\[ H_0: \mu_1 = \mu_2 = \cdots = \mu_k \]
\[ H_1: \text{pelo menos uma média difere das demais} \]
A estatística de teste é a razão entre o quadrado médio entre grupos e o quadrado médio residual:
\[ F = \frac{QM_{trat}}{QM_{res}} \]
Valores altos de \(F\) indicam maior evidência contra a hipótese nula.
Ajuste do modelo
m1 <- lm(tcm ~ especie, data = micelial)
summary(m1)
Call:
lm(formula = tcm ~ especie, data = micelial)
Residuals:
Min 1Q Median 3Q Max
-0.23667 -0.09667 0.01583 0.08833 0.28333
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.57167 0.05585 28.140 < 2e-16 ***
especieFaus -0.33500 0.07899 -4.241 0.000266 ***
especieFcor -0.25000 0.07899 -3.165 0.004047 **
especieFgra -0.66000 0.07899 -8.356 1.05e-08 ***
especieFmer -0.14500 0.07899 -1.836 0.078317 .
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.1368 on 25 degrees of freedom
Multiple R-squared: 0.7585, Adjusted R-squared: 0.7199
F-statistic: 19.63 on 4 and 25 DF, p-value: 2.028e-07anova(m1)Analysis of Variance Table
Response: tcm
Df Sum Sq Mean Sq F value Pr(>F)
especie 4 1.46958 0.36739 19.629 2.028e-07 ***
Residuals 25 0.46792 0.01872
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Parte 6 — Diagnóstico dos pressupostos da ANOVA
A ANOVA clássica assume:
- independência dos erros;
- normalidade dos resíduos;
- homogeneidade de variâncias.
Inspeção dos resíduos
hist(m1$residuals)
qqnorm(m1$residuals)
qqline(m1$residuals)
shapiro.test(m1$residuals)
Shapiro-Wilk normality test
data: m1$residuals
W = 0.9821, p-value = 0.8782Homogeneidade de variâncias
O teste de Bartlett avalia a hipótese de igualdade das variâncias entre grupos:
\[ H_0: \sigma_1^2 = \sigma_2^2 = \cdots = \sigma_k^2 \]
bartlett.test(tcm ~ especie, data = micelial)
Bartlett test of homogeneity of variances
data: tcm by especie
Bartlett's K-squared = 4.4367, df = 4, p-value = 0.3501Comentário
Assim como na análise anterior, os diagnósticos não devem ser interpretados apenas de forma mecânica. A inspeção gráfica dos resíduos é essencial para avaliar desvios importantes da normalidade e da homogeneidade.
Parte 7 — Médias ajustadas com emmeans e comparação de Tukey
Por que não comparar pares com vários testes t?
Depois que a ANOVA indica diferença global entre médias, surge a pergunta: quais grupos diferem entre si?
Uma estratégia inadequada seria fazer vários testes t independentes, pois isso inflaciona a probabilidade de erro do tipo I. Para contornar esse problema, utilizamos procedimentos de comparação múltipla que controlam esse erro, como o método de Tukey.
Médias marginais estimadas
O pacote emmeans calcula as médias ajustadas do modelo, também chamadas de médias marginais estimadas.
medias_m1 <- emmeans(m1, ~ especie)
medias_m1 especie emmean SE df lower.CL upper.CL
Fasi 1.572 0.0559 25 1.457 1.69
Faus 1.237 0.0559 25 1.122 1.35
Fcor 1.322 0.0559 25 1.207 1.44
Fgra 0.912 0.0559 25 0.797 1.03
Fmer 1.427 0.0559 25 1.312 1.54
Confidence level used: 0.95 Comparações múltiplas de Tukey
pairs(medias_m1, adjust = "tukey") contrast estimate SE df t.ratio p.value
Fasi - Faus 0.335 0.079 25 4.241 0.0023
Fasi - Fcor 0.250 0.079 25 3.165 0.0302
Fasi - Fgra 0.660 0.079 25 8.356 <0.0001
Fasi - Fmer 0.145 0.079 25 1.836 0.3765
Faus - Fcor -0.085 0.079 25 -1.076 0.8169
Faus - Fgra 0.325 0.079 25 4.115 0.0031
Faus - Fmer -0.190 0.079 25 -2.405 0.1469
Fcor - Fgra 0.410 0.079 25 5.191 0.0002
Fcor - Fmer -0.105 0.079 25 -1.329 0.6761
Fgra - Fmer -0.515 0.079 25 -6.520 <0.0001
P value adjustment: tukey method for comparing a family of 5 estimates Letras de agrupamento
Uma forma prática de resumir os resultados é usar letras para indicar grupos estatisticamente semelhantes. Médias seguidas pela mesma letra não diferem entre si ao nível de significância adotado.
medias_m1b <- cld(medias_m1, Letters = letters)
medias_m1b especie emmean SE df lower.CL upper.CL .group
Fgra 0.912 0.0559 25 0.797 1.03 a
Faus 1.237 0.0559 25 1.122 1.35 b
Fcor 1.322 0.0559 25 1.207 1.44 b
Fmer 1.427 0.0559 25 1.312 1.54 bc
Fasi 1.572 0.0559 25 1.457 1.69 c
Confidence level used: 0.95
P value adjustment: tukey method for comparing a family of 5 estimates
significance level used: alpha = 0.05
NOTE: If two or more means share the same grouping symbol,
then we cannot show them to be different.
But we also did not show them to be the same. Gráfico das médias com intervalos de confiança e letras
medias_m1b |>
ggplot(aes(x = reorder(especie, emmean), y = emmean, label = .group)) +
geom_point(size = 2) +
geom_errorbar(aes(ymin = lower.CL, ymax = upper.CL), width = 0.06) +
geom_text(hjust = 0, nudge_y = 0.12, size = 4) +
coord_flip() +
labs(
x = "",
y = "Taxa de crescimento micelial (mm/dia)"
) +
theme_classic()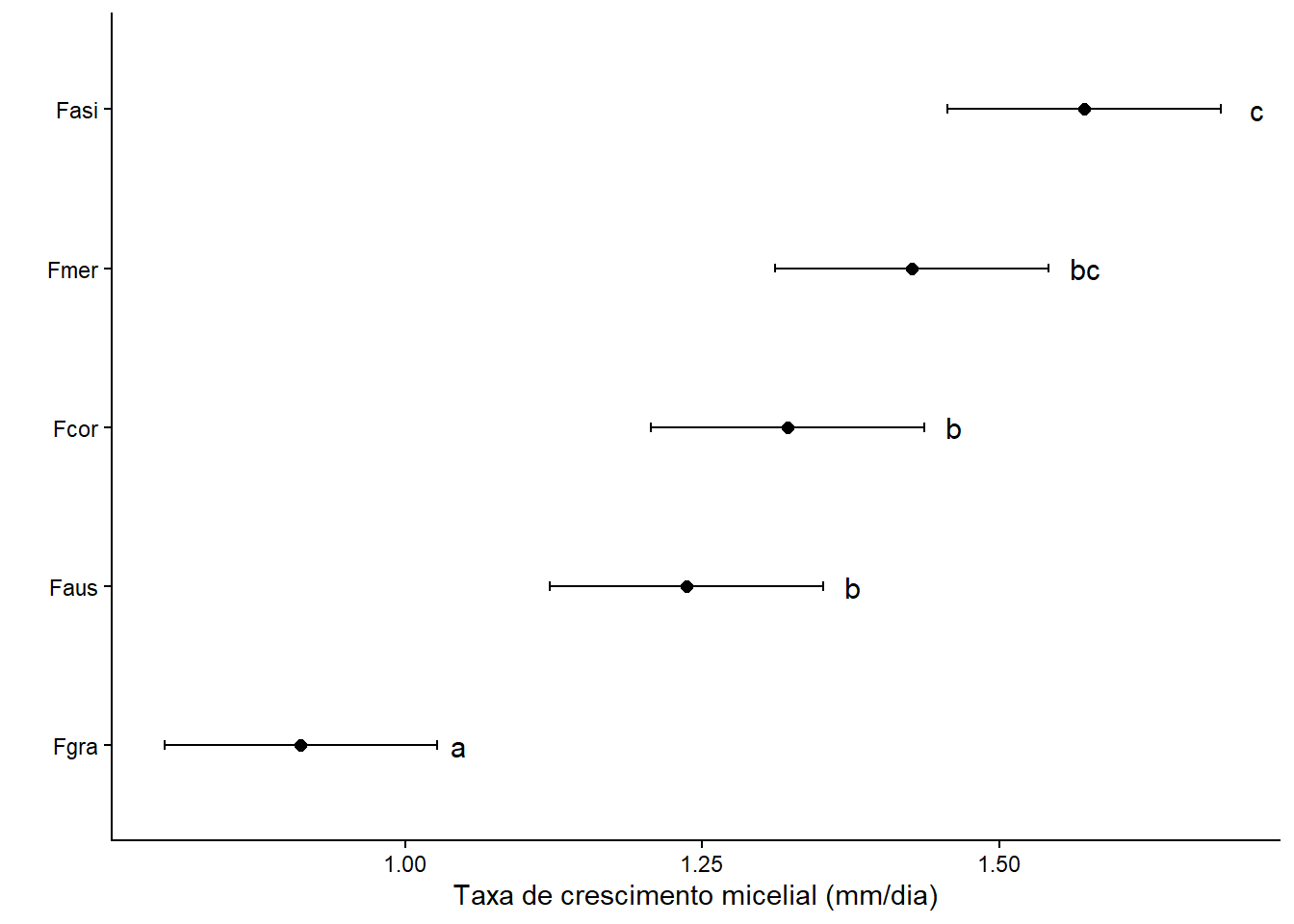
Parte 8 — Síntese conceitual da aula
1. Teste t para amostras independentes
Usado para comparar a média de dois grupos independentes.
- Unidade analítica em cada grupo é diferente.
- Exemplo desta aula: comparação da AUDPC entre tratamentos de irrigação.
2. Teste t pareado
Usado quando as duas medidas vêm dos mesmos indivíduos ou de unidades emparelhadas.
- O teste é realizado sobre as diferenças entre pares.
- Exemplo desta aula: comparação da acurácia dos mesmos avaliadores sob duas condições.
3. Teste de Wilcoxon pareado
Alternativa não paramétrica ao teste t pareado.
- Útil quando a distribuição das diferenças é muito assimétrica ou quando há clara violação da normalidade.
4. ANOVA
Usada para comparar três ou mais médias simultaneamente.
- Primeiro testa-se o efeito global.
- Depois, se necessário, investigam-se comparações múltiplas.
5. emmeans e Tukey
Permitem estimar médias ajustadas e comparar grupos com controle do erro associado a múltiplas comparações.
Parte 9 — Sugestões de interpretação para o relatório
Ao redigir resultados, procure separar claramente:
- descrição dos dados, com médias e medidas de dispersão;
- resultado do teste global, com estatística e valor de p;
- comparações específicas, quando cabíveis;
- interpretação biológica dos resultados.
Exemplo de estrutura textual:
A AUDPC média foi maior em um dos tratamentos de irrigação. O teste t para amostras independentes indicou diferença significativa entre as médias dos grupos (p < 0,05). No experimento com avaliadores, a acurácia diferiu entre as condições quando analisada de forma pareada. Para os dados de crescimento micelial, a ANOVA indicou efeito de espécie, e as comparações de Tukey permitiram identificar quais espécies apresentaram médias distintas.